[TOC]
基础目标:
可靠、可扩展、可维护的数据系统
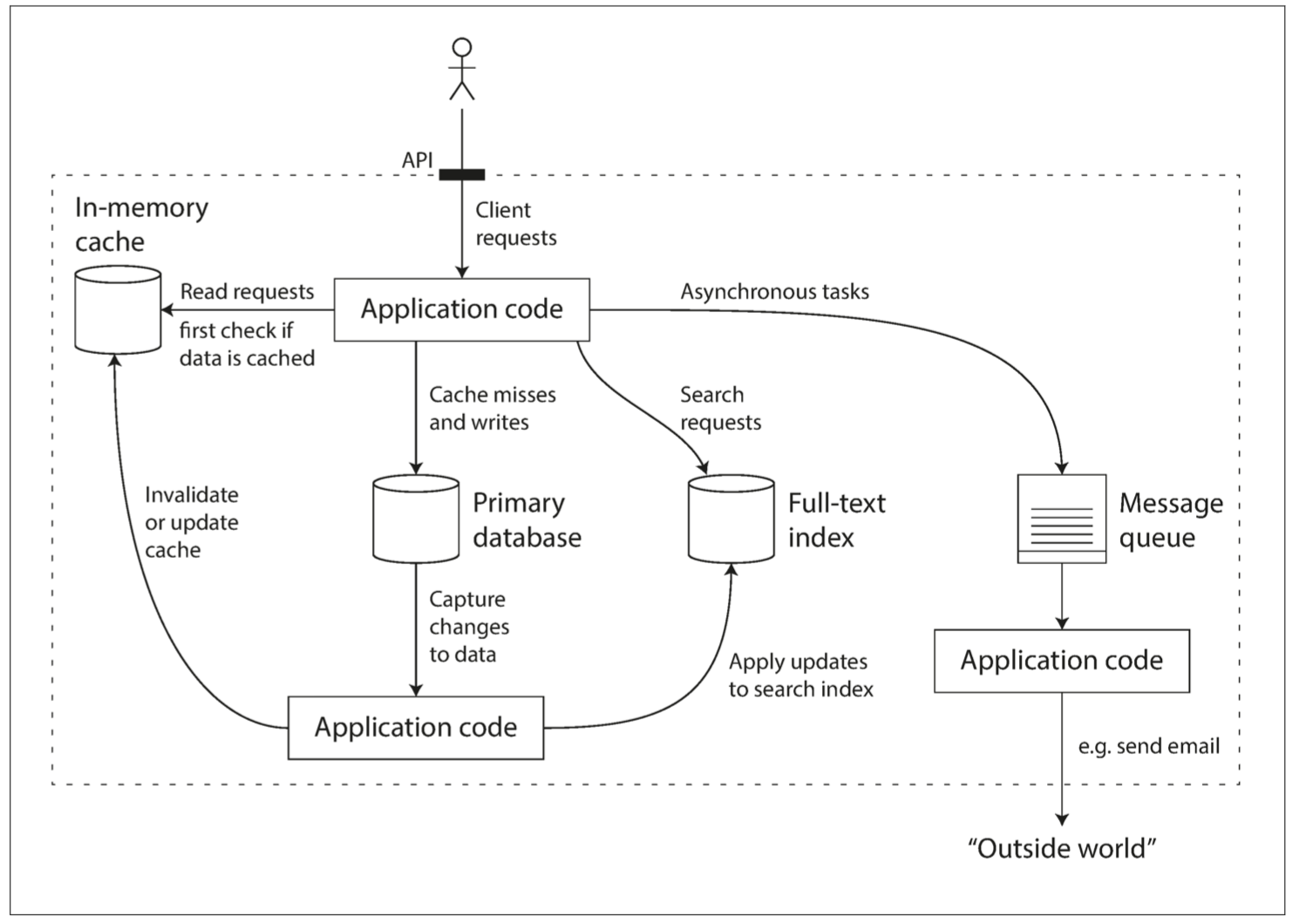
负载:
负载可以用一些称为负载参数(load parameters)的数字来描述。参数的最佳选择取决于系统架构,它可能是每秒向Web服务器发出的请求、数据库中的读写比率、聊天室中同时活跃的用户数量、缓存命中率或其他东西。除此之外,也许平均情况对你很重要,也许你的瓶颈是少数极端场景。
举例,发文的时间线,有两种实现方式
查数据库的方式
1
2
3
4
5SELECT tweets.*, users.*
FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user
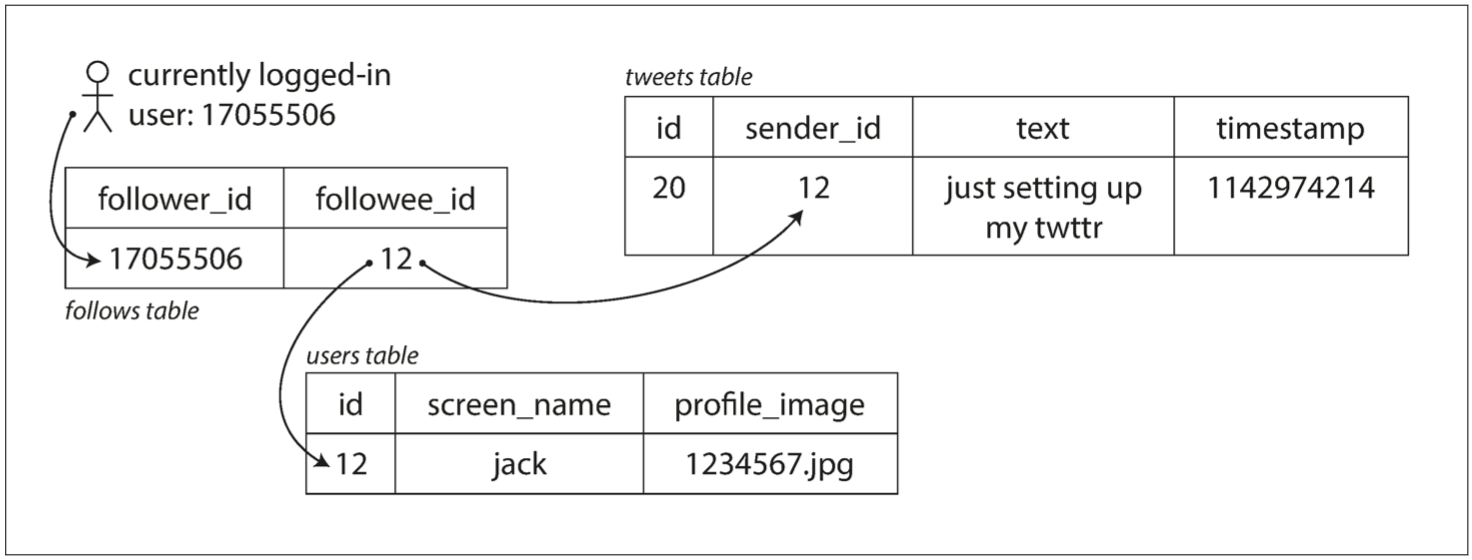
通过查询缓存的方式,为每个用户的主页时间线维护一个缓存,就像每个用户的推文收件箱(图1-3)。 当一个用户发布推文时,查找所有关注该用户的人,并将新的推文插入到每个主页时间线缓存中。 因此读取主页时间线的请求开销很小,因为结果已经提前计算好了
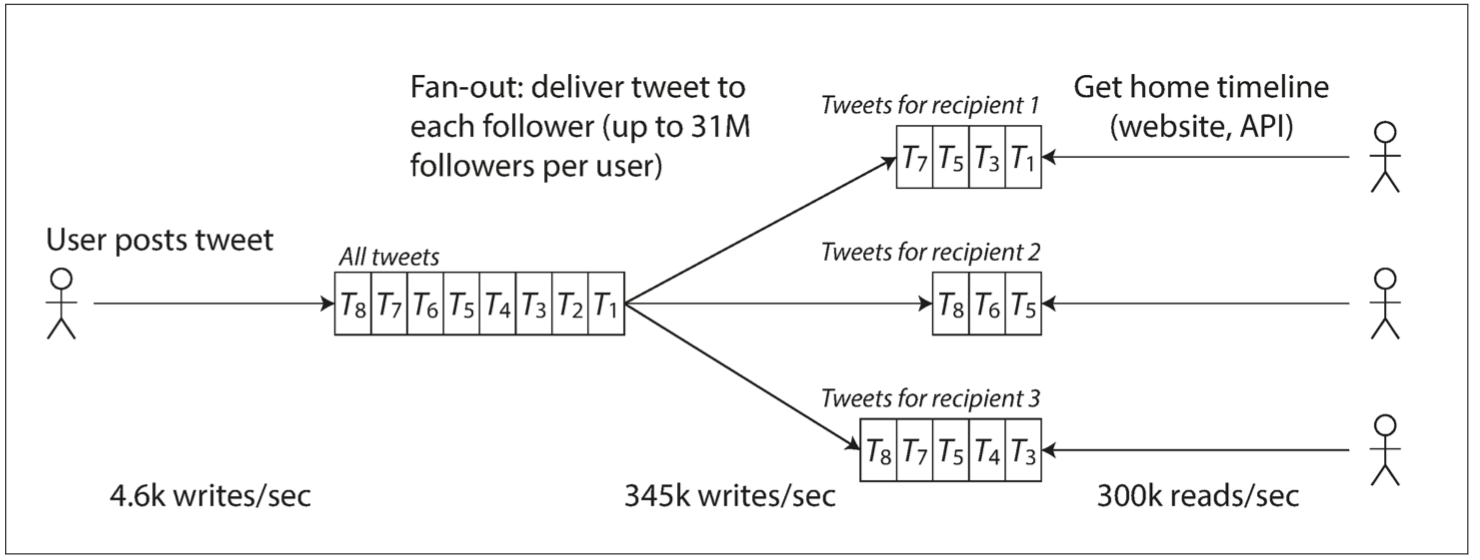
缺点在于,发推现在需要大量的额外工作。平均来说,一条推文会发往约75个关注者,所以每秒4.6k的发推写入,变成了对主页时间线缓存每秒345k的写入。但这个平均值隐藏了用户粉丝数差异巨大这一现实,一些用户有超过3000万的粉丝,这意味着一条推文就可能会导致主页时间线缓存的3000万次写入!及时完成这种操作是一个巨大的挑战——推特尝试在5秒内向粉丝发送推文
最后的折中:两种方法的混合。大多数用户发推时仍然是扇出写入粉丝的主页时间线缓存中。但是少数拥有海量粉丝的用户(即名流)被排除在外。当用户读取主页时间线时,来自所关注名流的推文都会单独拉取,并与用户的主页时间线缓存合并,如方法1所示。这种混合方法能始终如一地提供良好性能
性能考量:
关于在线系统的响应时间
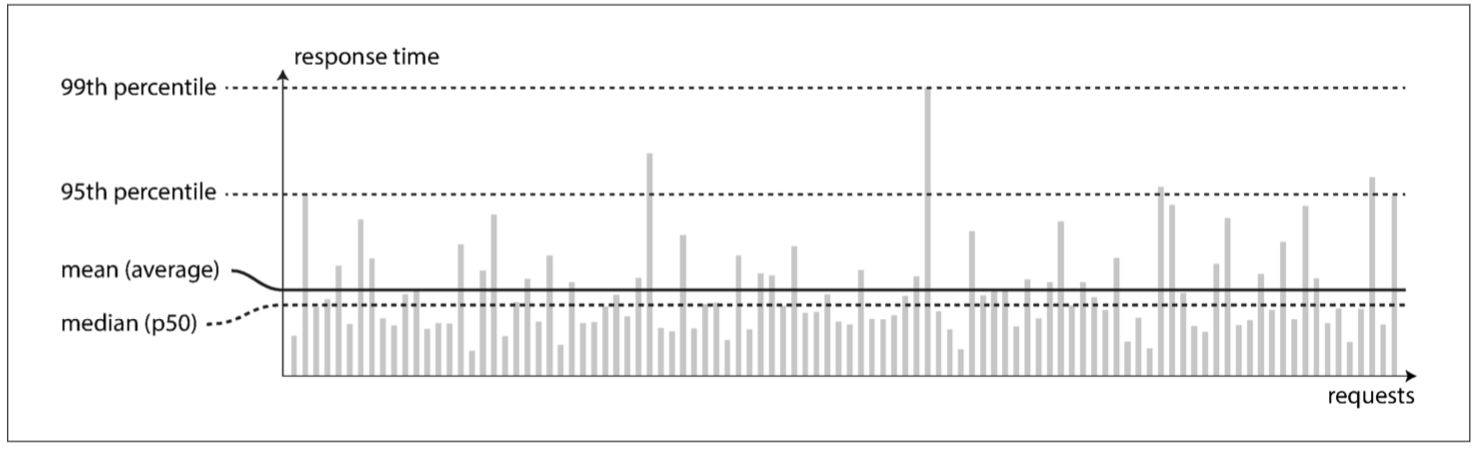
响应时间的高百分位点(也称为尾部延迟(tail percentil))非常重要,因为它们直接影响用户的服务体验。
应对负载的方法:水平扩展,垂直扩展,弹性等等
ActiveRecord框架
网络模型 vs 关系模型
存储与检索
最简单的数据库
1 |
|
注意后面的tail -n 1取最新的一个
我们只是追加写一个文件 - 所以我们如何避免最终用完磁盘空间?一个好的解决方案是通过在达到一定大小时关闭一个段文件,然后将其写入一个新的段文件来将日志分割成特定大小的段。然后我们可以对这些段进行压缩
压缩意味着在日志中丢弃重复的键,只保留每个键的最新更新
压缩以及合并
索引类型
哈希索引
SSTable (Sorted String Table)
- 好处:合并简单而高效,两个有序队列的合并排序;可以范围查询,因为有序;
在磁盘上维护有序结构是可能的(参阅“B-Tree”),但在内存保存则要容易得多。有许多可以使用的众所周知的树形数据结构,例如红黑树或AVL树【2】。使用这些数据结构,您可以按任何顺序插入键,并按排序顺序读取它们。
现在我们可以使我们的存储引擎工作如下:
- 写入时,将其添加到内存中的平衡树数据结构(例如,红黑树)。这个内存树有时被称为memtable。
- 当memtable大于某个阈值(通常为几兆字节)时,将其作为SSTable文件写入磁盘。这可以高效地完成,因为树已经维护了按键排序的键值对。新的SSTable文件成为数据库的最新部分。当SSTable被写入磁盘时,写入可以继续到一个新的memtable实例。
- 为了提供读取请求,首先尝试在memtable中找到关键字,然后在最近的磁盘段中,然后在下一个较旧的段中找到该关键字。
- 有时会在后台运行合并和压缩过程以组合段文件并丢弃覆盖或删除的值。
用SSTable制作LSM树
为了使数据库对崩溃具有韧性,B树实现通常会带有一个额外的磁盘数据结构:预写式日志(WAL,也称为重做日志)。这是一个只能追加的文件,每个B树修改都可以应用到树本身的页面上。当数据库在崩溃后恢复时,这个日志被用来恢复B树回到一致的状态
比较B树和LSM树
根据经验,LSM树通常写速度更快,而B树被认为读取速度更快【23】
B树的写入逻辑:必须至少两次写入每一段数据:一次写入预先写入日志,一次写入树页面本身(也许再次分页)。即使在该页面中只有几个字节发生了变化,也需要一次编写整个页面的开销
LSM的缺点:
日志结构存储的缺点是压缩过程有时会干扰正在进行的读写操作。尽管存储引擎尝试逐步执行压缩而不影响并发访问,但是磁盘资源有限,所以很容易发生请求需要等待而磁盘完成昂贵的压缩操作。对吞吐量和平均响应时间的影响通常很小,但是在更高百分比的情况下,对日志结构化存储引擎的查询响应时间有时会相当长,而B树的行为则相对更具可预测性
在聚集索引(clustered index)(在索引中存储所有行数据)和非聚集索引(nonclustered index)(仅在索引中存储对数据的引用)之间的折衷被称为包含列的索引(index with included columns)或覆盖索引(covering index),其存储表的一部分在索引内【33】。这允许通过单独使用索引来回答一些查询(这种情况叫做:索引覆盖了(cover)查询
反直觉的是,内存数据库的性能优势并不是因为它们不需要从磁盘读取的事实。即使是基于磁盘的存储引擎也可能永远不需要从磁盘读取,因为操作系统缓存最近在内存中使用了磁盘块。相反,它们更快的原因在于省去了将内存数据结构编码为磁盘数据结构的开销
| 属性 | 事务处理 OLTP | 分析系统 OLAP |
|---|---|---|
| 主要读取模式 | 查询少量记录,按键读取 | 在大批量记录上聚合 |
| 主要写入模式 | 随机访问,写入要求低延时 | 批量导入(ETL),事件流 |
| 主要用户 | 终端用户,通过Web应用 | 内部数据分析师,决策支持 |
| 处理的数据 | 数据的最新状态(当前时间点) | 随时间推移的历史事件 |
| 数据集尺寸 | GB ~ TB | TB ~ PB |
编码与演化
系统想要继续顺利运行,就需要保持兼容性,向后兼容与向前兼容。