While it is true that Redshift is based off PostgreSQL it has been so heavily modified
There are 3 important aspects in big data architecture: Scalability, Scalability and Scalability (maintaining performance despite ever increasing volumes of data)
Such “trends” include:
- The rise of noSQL database management systems (To solve the inherent scalability problems of relational databases)
- The rise of functional programming paradigms (Make concurrency easier to reason with. Big data processing systems are often — by there very nature — distributed and highly concurrent)

Spark: It also uses a DAG (Directed Acyclic Graph) Engine to optimize workflows. The DAG engine essentially takes the tasks that needs to be completed and works backwards to determine the most optimum way to carry them out.
Hadoop was designed for storing large amounts of data and running batch processing applications against said data (known as an OLAP system). As such It is unsuitable for serving customer facing applications such as web applications (OLTP system).
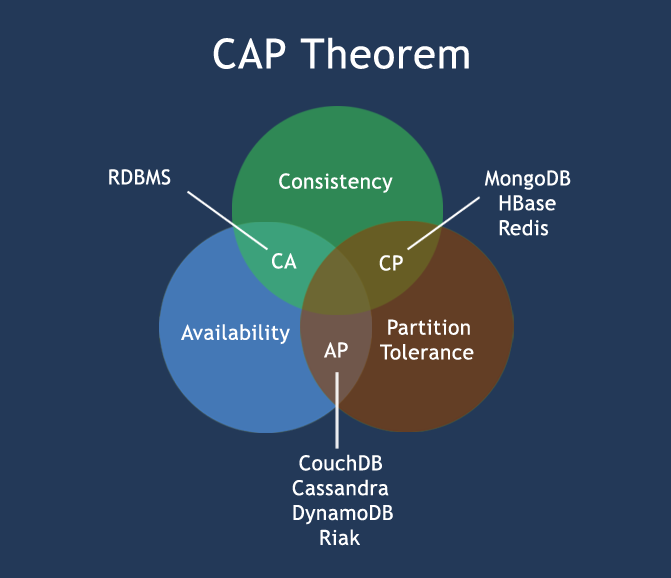
最新的是解决CA问题的是google的spannr服务。类似于Tidb
As a Data Engineer you may be involved in projects such as the following:
- Building ETL (Extract-Transform-Load) pipelines: Not to be confused with “data ingestion” which is simply moving data from one place to another. ETL pipelines are a fundamental component of any data system. They extract data from many disparate sources, transform (aka wrangling) the data (often making it fit the data model defined by your data warehouse) then load said data into your data warehouse. These are systems built from scratch using programming languages such as Python, Java, Scala, Go, etc.
- Building metric analysis tools: Tools used to query the data pipeline for statistics such as customer engagement, growth or operational efficiency.
- Building/Maintaining Data Warehouse/Lake: Data engineers are the “librarians” of the data warehouse, cataloguing and organizing metadata. They must also define the processes by which other people in your organisation load or extract data to/from the warehouse (As a gatekeeper of sorts).