To give some perspective on the data scale at Flipkart, FDP currently manages a 800+ nodes Hadoop cluster to store more than 35 PB of data. We also run close to 25,000 compute pipelines on our Yarn cluster. Daily TBs of data is ingested into FDP and it also handles data spikes because of sale events. The tech stack majorly comprises of HDFS, Hive, Yarn, MR, Spark, Storm & other API services supporting the meta layer of the data
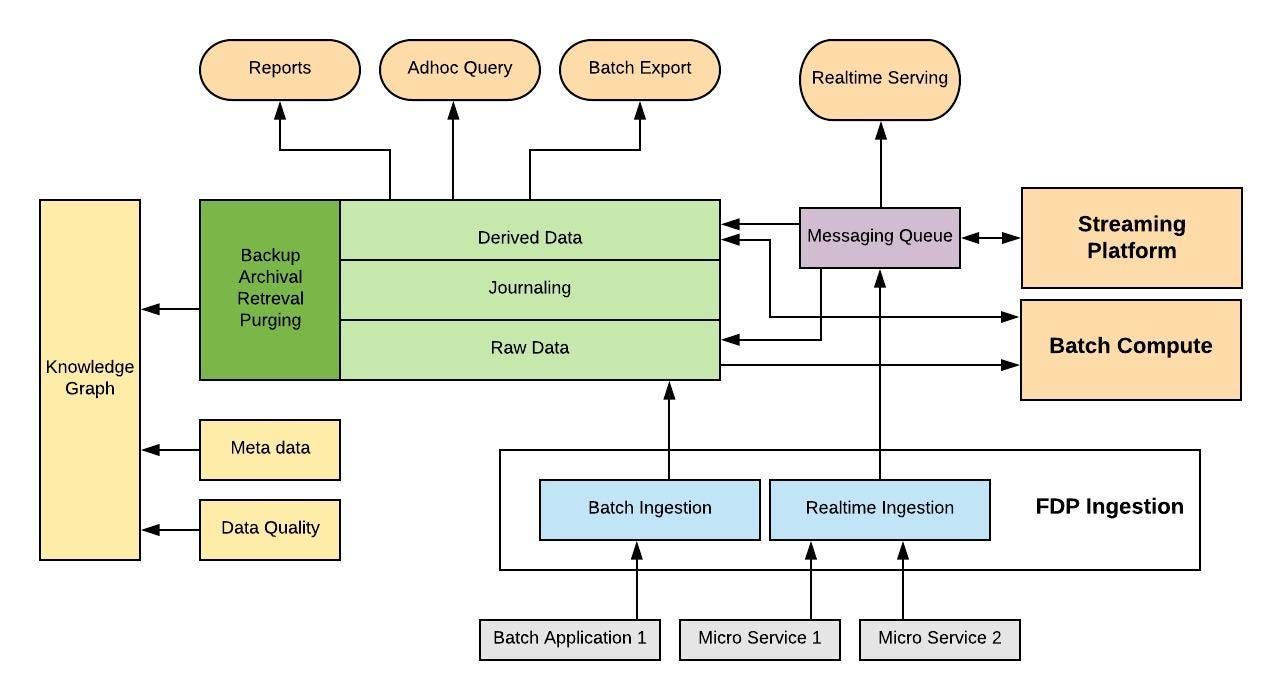
Overall FDP can be broken down into following high level components.
- Ingestion System
- Batch Data Processing System
- Real time Processing System
- Report Visualization
- Query Platform
The streaming platform allows near real time aggregations to be built on all the ingested data. We also have the ability of generating rolling window aggregations i.e. 5 mins, 1 hour, 1 day, 1 month or Historic for each of the metrics.
Apache Lens 接入hive等
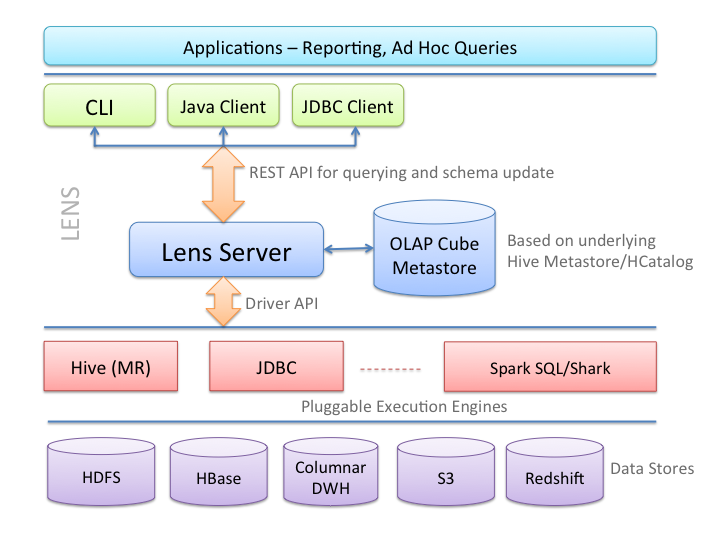
ETL
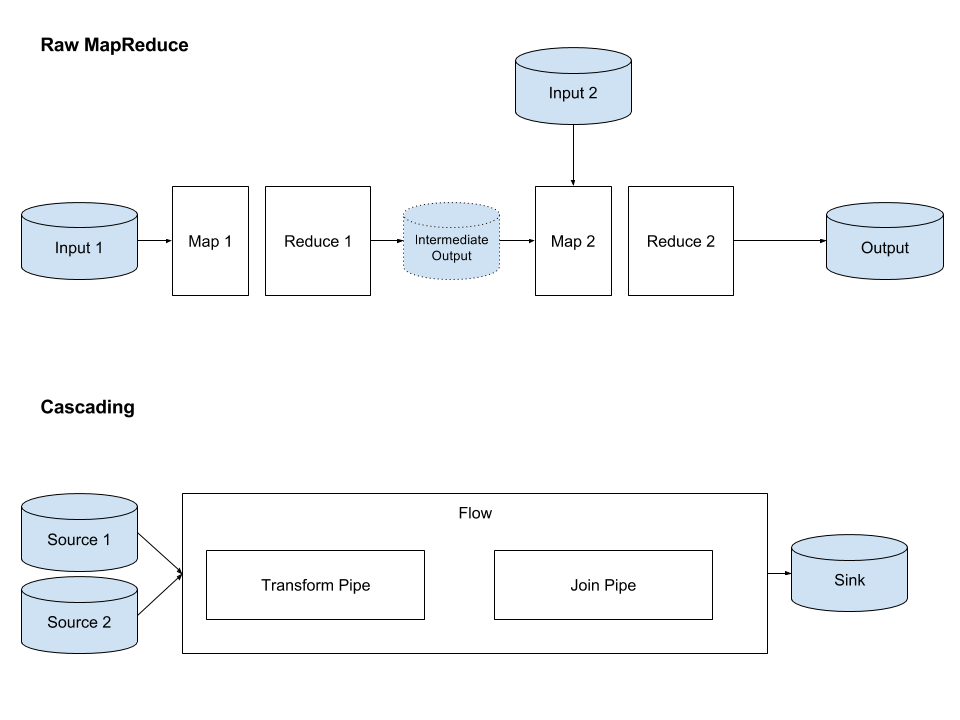
At the onset of Recommendation platform, we started with raw MapReduce(MR) which gave us granular control over our pipeline but required a lot of boilerplate code for performing joins and aggregations that constituted the building blocks of our ETL flow
mapreduce vs cascading
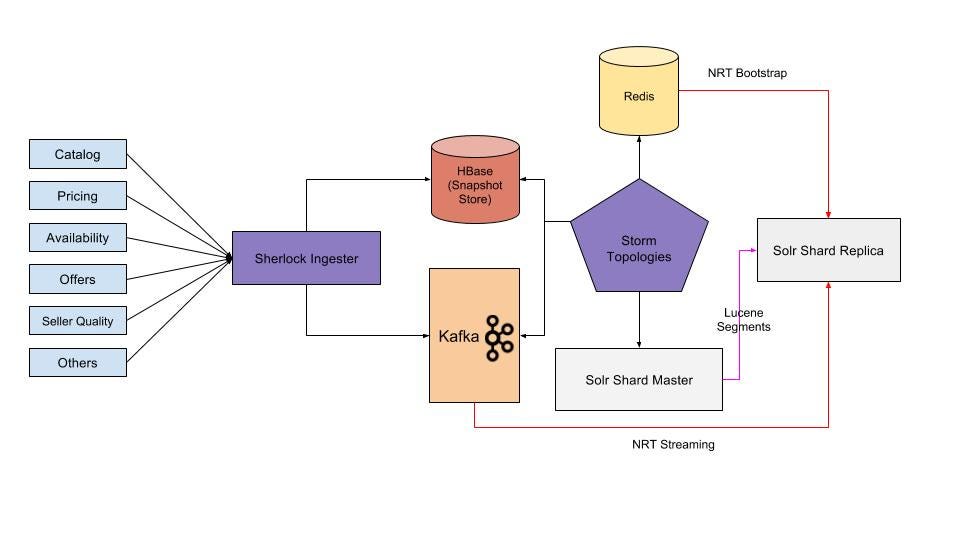
REAL TIME SEACH INDEX
The Sherlock team developed an innovative solution (NRT data store) to deliver near real-time search results and presented it at Lucene Revolution video
高频繁的更新操作,