GAN is almost always explained like the case of a counterfeiter (Generative) and the police (Discriminator). Initially, the counterfeiter will show the police a fake money. The police says it is fake. The police gives feedback to the counterfeiter why the money is fake. The counterfeiter attempts to make a new fake money based on the feedback it received. The police says the money is still fake and offers a new set of feedback. The counterfeiter attempts to make a new fake money based on the latest feedback. The cycle continues indefinitely until the police is fooled by the fake money because it looks real
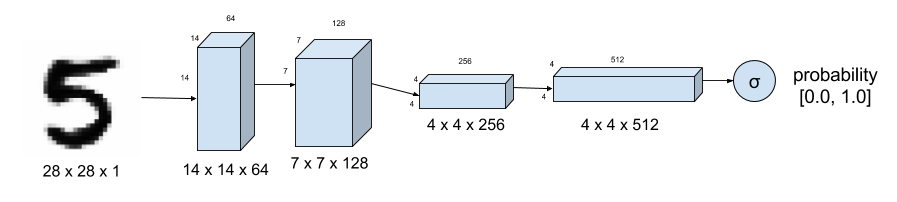
Figure 1. Discriminator of DCGAN tells how real an input image of a digit is. MNIST Dataset is used as ground truth for real images. Strided convolution instead of max-pooling down samples the image.
1 | self.D = Sequential() |
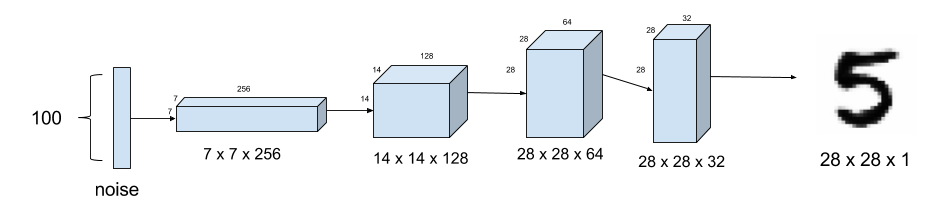
Figure 2. Generator model synthesizes fake MNIST images from noise. Upsampling is used instead of fractionally-strided transposed convolution.
1 | self.G = Sequential() |

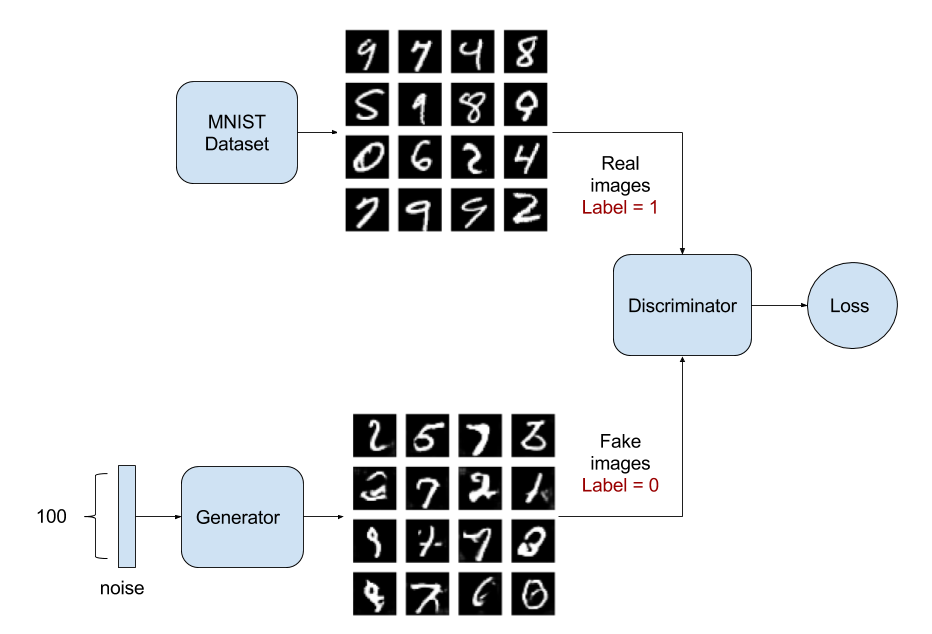
1 | images_train = self.x_train[np.random.randint(0, |
Some tips
Training GAN models requires a lot of patience due to its depth. Here are some pointers:
- Problem: generated images look like noise. Solution: use dropout on both Discriminator and Generator. Low dropout values (0.3 to 0.6) generate more realistic images.
- Problem: Discriminator loss converges rapidly to zero thus preventing the Generator from learning. Solution: Do not pre-train the Discriminator. Instead make its learning rate bigger than the Adversarial model learning rate. Use a different training noise sample for the Generator.
- Problem: generator images still look like noise. Solution: check if the activation, batch normalization and dropout are applied in the correct sequence.
- Problem: figuring out the correct training/model parameters. Solution: start with some known working values from published papers and codes and adjust one parameter at a time. Before training for 2000 or more steps, observe the effect of parameter value adjustment at about 500 or 1000 steps.
尝试使用kaggle来做下试验?
tips:
在进行深度学习的时候,先尝试将相关图能画出来,讲流程图能画出来