倒排索引
倒排的hash冲突问题,通过正排的索引,辅助倒排的关系验证功能
- 所谓的查询,就是 HashMap.get(XX) 获取 list
- 所谓的竞价排名,就是这个 list 根据 money 去排序
- 所谓的广告植入,就是这个广告本来不在 list 里面,然后被强插进去
- 。。。
也就是正排的索引在竞价排名中起作用
feed流不同于搜索引擎部分,就是在于hash的函数不一样,提取兴趣点
多源融合
- 基于话题推荐 用户关注了 T 话题,用户 Feed 流里要有话题 T 相关的数据
- 基于行为推荐 用户发生了动作 A,Feed 流里要有动作 A 相关的数据
- 基于算法推荐 根据用户行为计算特征向量,推出与用户向量距离最近的数据
反复拉取->条目反序列化->过滤->是否足够->召回排序->Top100->算法排序
拉取权重的控制粒度:池子、库、分组。首页基于「源」的概念控制比例,而「源」是一个虚拟的组合。这个「源」的组合里,可以包括指定的几个池子,特定的几个库,抑或某些分组。
召回排序在选择 Top 100 时,特定「源」被召回的条目数为 100 * ratio。通过「源」的概念,可以保证特定组合召回权重。
每一层排序策略不同,通过筛选可以减少后续环节的计算量,通过排序保证每个环节最「恰当」的数据可被选出。
- 每个池子的 Top N,根据本池子的热度分 (静态的,所有用户一样)
- 召回排序 Top 100, 根据用户的兴趣分 (动态的,与用户的实时兴趣相关)
- 算法排序,用户最喜欢的 Top 7
使用redis module ,加入filter module以及使用zset的方式,
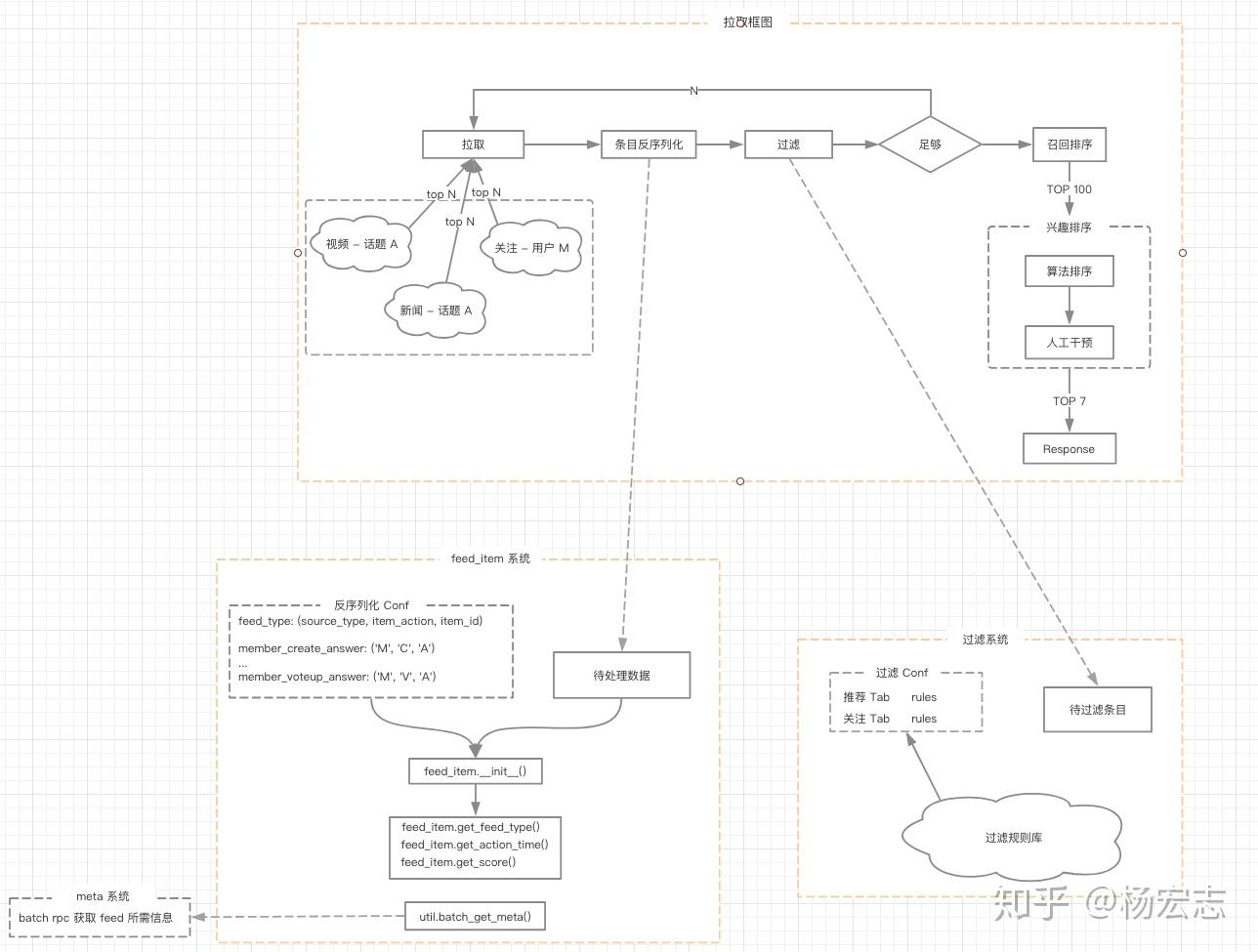
面向「工程」、面向「合作」,是上个 Q 架构演进的指导思想。只有易学习、易维护的架构才是恰当的架构。如何保证工程团队高效工作,尽力降低人力成本,便是这代架构的最大挑战。