背景
spark 1.6.2 -> spark 2.2
内存中的数据组织形式

在内存中,改成了以列式存储为主
(1) 与numpy或者tensorflow接入时可实现zero serialization(零序列化)
(2) 与Spark的in-memory columnar-cache无缝兼容
(3) 更利于压缩技术的引入
CBO
基于成本的优化器CBO,是根据计算出的所有可能的物理计划的代价,选择代价最小的物理执行计划。关键点在于能评估一个物理执行计划的代价。
HashJoin中build side and probe side中的问题
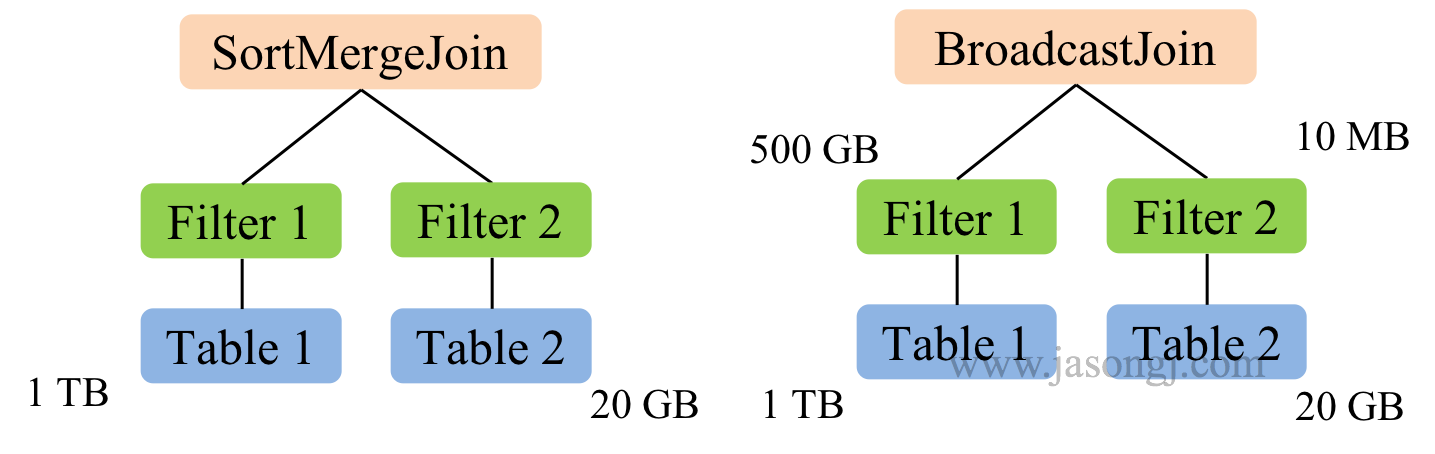
在 Spark SQL 中,Join主要有两种执行方式,Shuffle-based Join, BroadcastJoin。Shuffle-based Join会有Shuffle,代价比较。BroadcastJoin不需要shuffle,但要求至少有一张表足够小,这样就能通过Broadcast机制,广播到每个Executor中。
如下图所示,在没CBO的情况下,SparkSQL通过spark.sql.autoBroadcastJoinThreshold来判断是否选择BroadcastJoin(默认值为10MB)。如果判断基于原始表大小,会选用SortMergeJoin。
在有CBO的情况下,经过Filter后的Table 2的大小正好满足小于10MB的情况下,会正确地采用性能更好的BroadcastJoin。
- 并行的join的情况