NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries
针对noSQL部分,schemas are implicit in a schemaless system as the code that reads the data needs to account for the structure and the variations in the data (“schema-on-read”)
we have implemented NMDB as a “schema-on-write” system — data is validated against schema at the time of writing to NMDB
Within the NMDB system, Media Data Validation Service (MDVS), is the component that makes sure the data being written to NMDB is in compliance with an aforementioned schema
a DataStore is characterized by the three-tuple (1) a namespace, (2) a media analysis type (e.g., video shot boundary data), and (3) a version of the media analysis type (different versions of a media analysis correspond to different data schemas)
an NMDB DS is also associated with a single MID schema. However unlike the media data schema, MID schema is immutable
These business requirements motivated us to incorporate immutability and read-after-write consistency as fundamental precepts while persisting data in NMDB
MDPS uses local quorum for reads and writes to guarantee read-after-write consistency. 这个的含义是?
关于查询
Media Data Query Service (MDQS)
Media Data Analysis Service (MDAS)
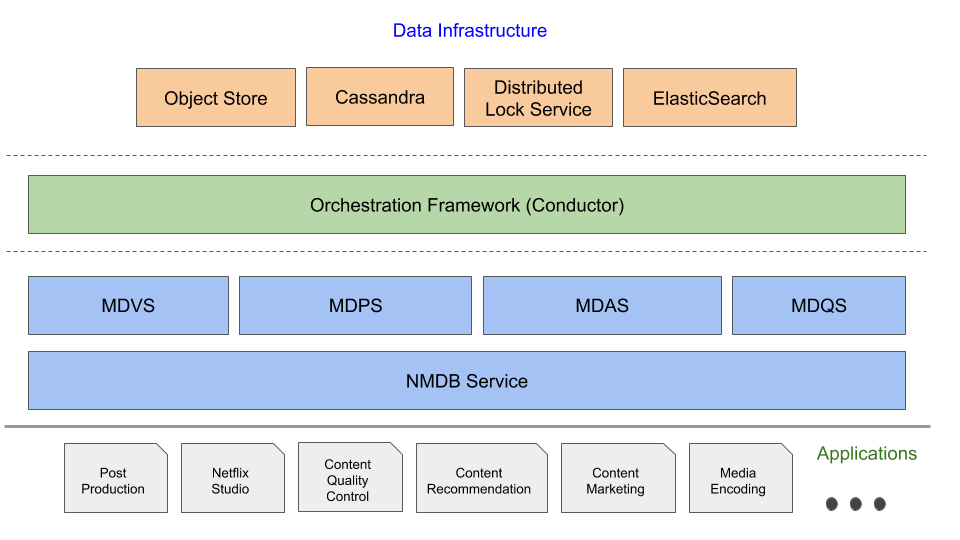
We use the Conductor orchestration framework to coordinate and execute workflows related to the NMDB Create, Read, Update, Delete (CRUD) operations and for other asynchronous operations such as querying. Conductor helps us achieve a high degree of service availability and data consistency across different storage backends