var pool = sync.Pool{ New: func()interface{} { returnnew(Small) }, }
//go:noinline funcinc(s *Small) { s.a++ }
funcBenchmarkWithoutPool(b *testing.B) { var s *Small for i := 0; i < b.N; i++ { for j := 0; j < 10000; j++ { s = &Small{ a: 1, } b.StopTimer(); inc(s); b.StartTimer() } } }
funcBenchmarkWithPool(b *testing.B) { var s *Small for i := 0; i < b.N; i++ { for j := 0; j < 10000; j++ { s = pool.Get().(*Small) s.a = 1 b.StopTimer(); inc(s); b.StartTimer() pool.Put(s) } } }
Since the loop has 10k iterations, the benchmark that does not use the pool made 10k allocations on the heap vs only 3 for the benchmark with pool.
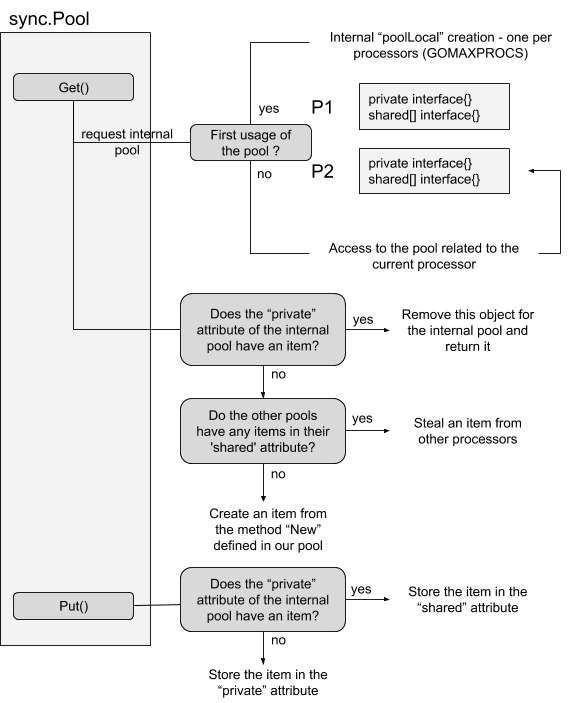
Go version 1.13 brings a new doubly-linked listas a shared pool that removes the lock and improves the shared access.
With this new chained pool, each processor with push and pop at the head of its queue while the shared access will pop from the tail. 大小的增长,类似于hashmap的增长
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// Drop victim caches from all pools. for _, p := range oldPools { p.victim = nil p.victimSize = 0 }
// Move primary cache to victim cache. for _, p := range allPools { p.victim = p.local p.victimSize = p.localSize p.local = nil p.localSize = 0 }
// The pools with non-empty primary caches now have non-empty // victim caches and no pools have primary caches. oldPools, allPools = allPools, nil