Mesa
mesa的预聚合数据模型
针对广告的背景,原始数据没有意义,但查询的时候需要有各种维度的数据
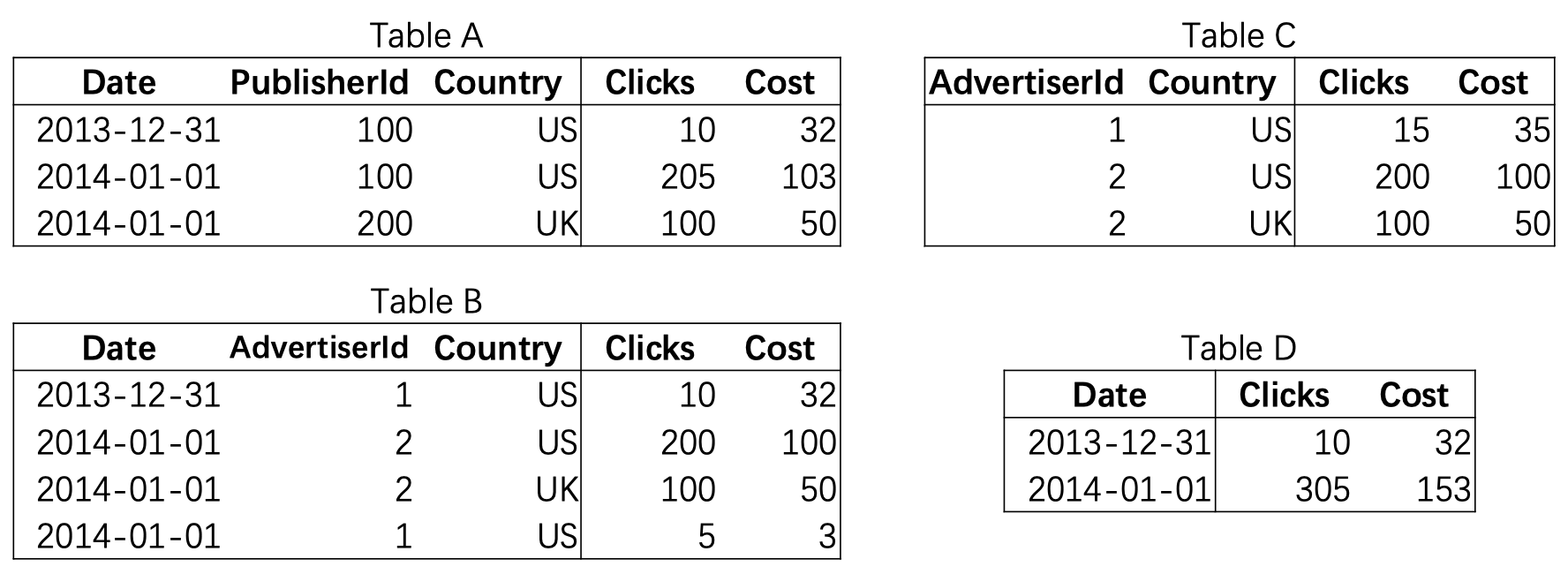
上面的 Table A~D 其实表示的是同一批原始数据的在四个不同维度的聚合结果,供不同的业务查询使用
只支持按照batch来更新,同spark-streaming天然贴合?
每次导入的 delta 数据不会立即和基线数据合并,而是会先以单独的文件存在,积累一定数量后再做 Compaction
kylin的预聚合?
Doris
支持以下三种模型的表:
- Aggregate 表:需要定义 Key 列和 Value 列,Key 列相同的数据行会自动合并,合并时 Value 列的数据按预先定义好的聚合函数进行聚合
- Duplicate 表:不会自动合并 Key 相同的数据,其语义类似于其他数据库中的关系表,Key 表示表的排序键(sort key)而不是唯一键
- Uniq 表,Key 列相同时新的行覆盖(Replace)旧的行,本质上是一种特化的 Aggregate 表
Base->ROLLUP
物化视图的概念,允许用户基于明细表(Duplicate 表)定义预聚合。Doris 的物化视图仅支持定义聚合(Group-By)