k8e intro
FiloDB
FiloDB is designed to scale to ingest and query millions of discrete time series. A single time series consists of data points that contain the same partition key. Successive data points are appended. Each data point must contain a timestamp. Examples of time series:
- Individual operational metrics
- Data from a single IoT device
- Events from a single application, device, or endpoint
主要是针对TSDB?这种?
关于tags部分的查询
docker's second death
Swarm was eventually overwhelmed (pun intended) by the uptake of Kubernetes across the industry, and this was when it died the first time: it lost the platform wars and became the very first commodity in the cloud native ecosystem.

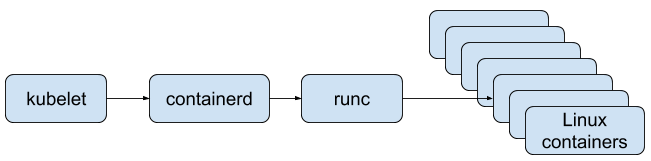
Docker was never the runtime.
Huge Page Improve database
default page 4KB
huge page 2MB
1 | cat /proc/meminfo | grep huge |
作为 Linux 从 2.6.32 引入的新特性,HugePages 能够提升数据库、Hadoop 全家桶等占用大量内存的服务的性能,该特性对于常见的 Web 服务以及后端服务没有太多的帮助,反而可能会影响服务的性能
- HugePages 可以降低内存页面的管理开销;
- HugePages 可以锁定内存,禁止操作系统的内存交换和释放;
大内存,减少页表层级,减少获取大内存的次数,提高缓存命中率
如果我们使用 Linux 中默认的 4KB 内存页,那么 CPU 在访问对应的内存时需要分别读取 PGD、PUD、PMD 和 PTE 才能获取物理内存,五层页表
锁定内存,减少swap带来的抖动