How much confidence we can have in the complex systems that we put into production?
Even when all of the individual services in a distributed system are functioning properly, the interactions between those services can cause unpredictable outcomes. Unpredictable outcomes, compounded by rare but disruptive real-world events that affect production environments, make these distributed systems inherently chaotic
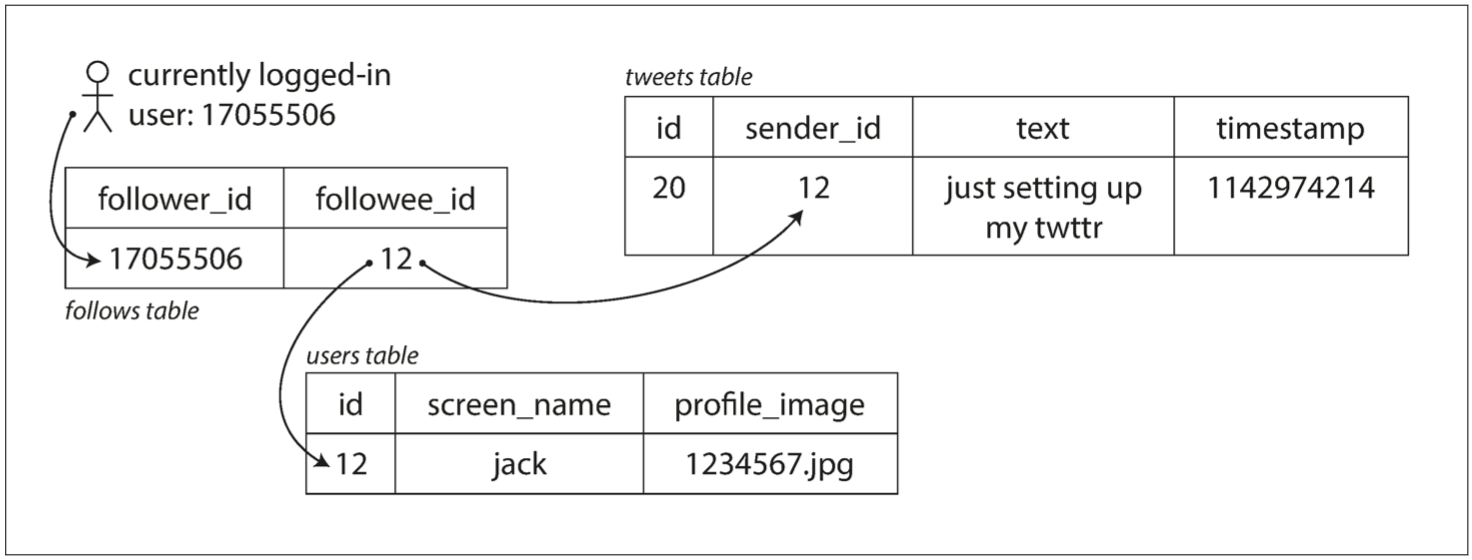
SELECT tweets.*, users.* FROM tweets JOIN users ON tweets.sender_id = users.id JOIN follows ON follows.followee_id = users.id WHERE follows.follower_id =current_user
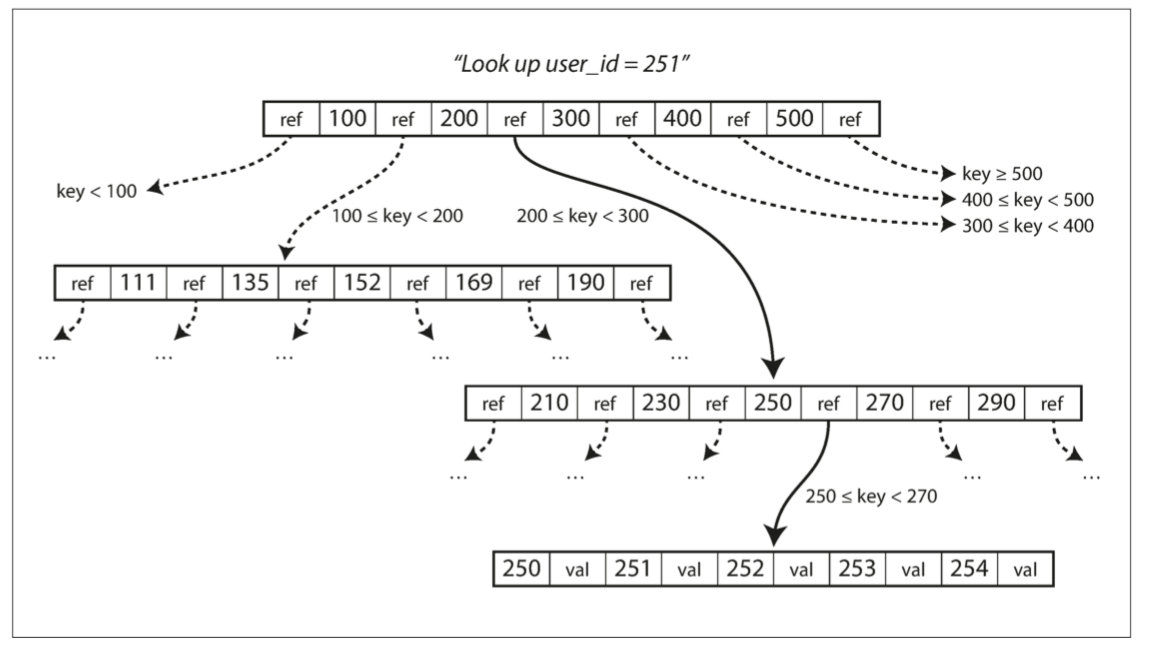
在聚集索引(clustered index)(在索引中存储所有行数据)和非聚集索引(nonclustered index)(仅在索引中存储对数据的引用)之间的折衷被称为包含列的索引(index with included columns)或覆盖索引(covering index),其存储表的一部分在索引内【33】。这允许通过单独使用索引来回答一些查询(这种情况叫做:索引覆盖了(cover)查询