.git目录下
1 | ls |
新版本Git不再使用branches目录
有四個重要的檔案或目錄:HEAD 及 index 檔,objects 及 refs 目錄。這些是 Git 的核心部分。objects 目錄存放所有資料內容,refs 目錄存放指向資料 (分支) 的提交物件的指標,HEAD 檔指向目前分支,index 檔保存了暫存區域資訊
通過 cat-file 命令可以將資料內容取回。該命令是查看 Git 對象的瑞士軍刀。傳入 -p 參數可以讓 cat-file 命令輸出資料內容的類型:
1 | git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4 |
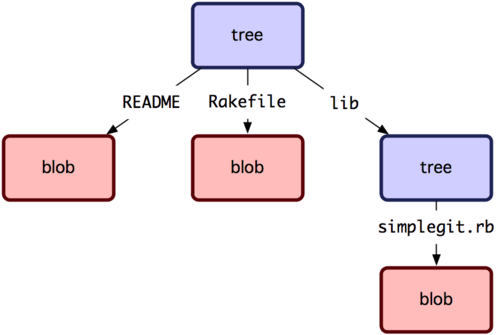
Git 以一種類似 UNIX 檔案系統但更簡單的方式來保存內容。所有內容以 tree 或 blob 物件保存,其中 tree 物件對應於 UNIX 中的目錄,blob 物件則大致對應於 inodes 或檔案內容。一個單獨的 tree 物件包含一條或多條 tree 記錄,每一條記錄含有一個指向 blob 或子 tree 物件的 SHA-1 指標,並附有該物件的許可權模式 (mode)、類型和檔案名資訊。