This tends to rule out cryptographic ones like SHA-1or MD5. Yes they are well distributed but they are also too expensive to compute — there are much cheaper options available. Something like MurmurHash is good, but there are slightly better ones out there now. Non-cryptographic hash functions like xxHash, MetroHash or SipHash1–3 are all good replacements.
1
server := serverList[hash(key) % N]
What are the downsides of this approach? The first is that if you change the number of servers, almost every key will map somewhere else. This is bad.
optimal option
When adding or removing servers, only 1/nth of the keys should move.
In practice, each server appears multiple times on the circle. These extra points are called “virtual nodes”, or “vnodes”. This reduces the load variance among servers. With a small number of vnodes, different servers could be assigned wildly different numbers of keys. 引入虚拟节点来管理
One of the other nice things about ring hashing is that the algorithm is straight-forward.
1 2 3 4 5 6 7 8 9 10
func(m *Map) Add(nodes ...string) { for _, n := range nodes { for i := 0; i < m.replicas; i++ { hash := int(m.hash([]byte(strconv.Itoa(i) + " " + n))) m.nodes = append(m.nodes, hash) m.hashMap[hash] = n } } sort.Ints(m.nodes) }
each one is hashed m.replicastimes with slightly different names ( 0 node1, 1 node1, 2 node1, …)
注意这里有replicas的概念,这样子多写几份?然后是对于nodes进行排序,方便进行binary search during lookup
funcHash(key uint64, numBuckets int)int32 { var b int64 = -1 var j int64 for j < int64(numBuckets) { b = j key = key*2862933555777941757 + 1 j = int64(float64(b+1) * (float64(int64(1)<<31) / float64((key>>33)+1))) } returnint32(b) }
It then uses the random numbers to “jump forward” in the list of buckets until it falls off the end
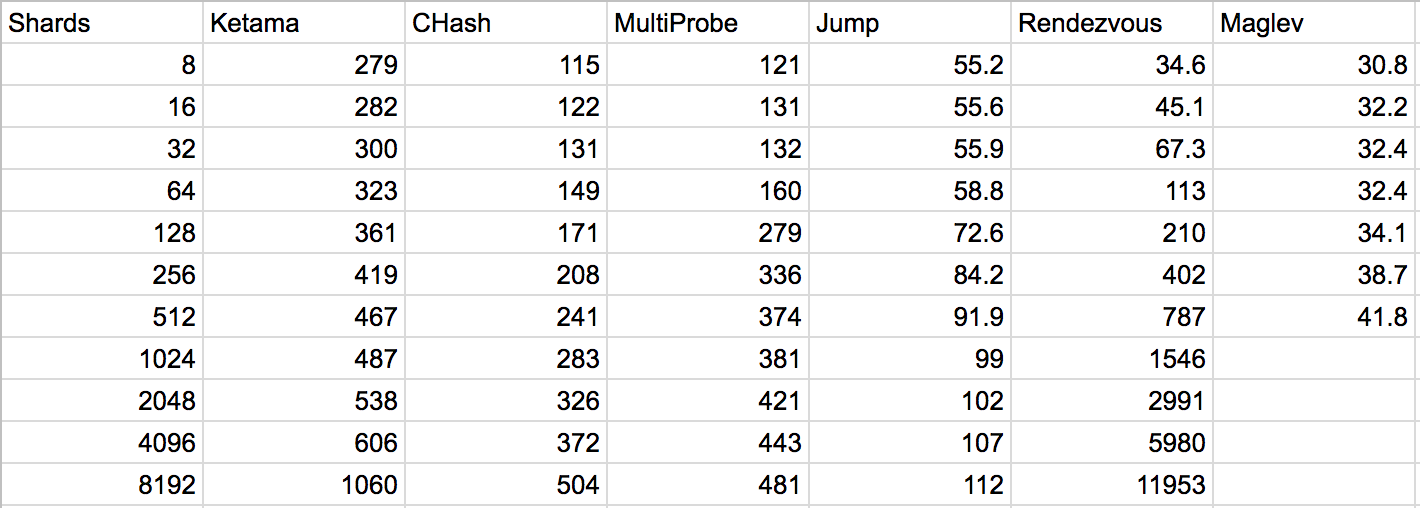
It’s fast and splits the load evenly. What’s the catch? The main limitation is that it only returns an integer in the range 0..numBuckets-1. It doesn’t support arbitrary bucket names. (With ring hash, even if two different instances receive their server lists in a different order, the resulting key mapping will still be the same.)
Multi-Probe Consistent Hashing
The basic idea is that instead of hashing the nodes multiple times and bloating the memory usage, the nodes are hashed only once but the key is hashed ktimes on lookup and the closest node over all queries is returned. The value of k is determined by the desired variance. For a peak-to-mean-ratio of 1.05 (meaning that the most heavily loaded node is at most 5% higher than the average), k is 21. With a tricky data structure you can get the total lookup cost from O(k log n) down to just O(k). My implementation uses the tricky data structure.