defget_vector_from_string(input_s): global max_features vector_x = [] for i in input_s: if i notin feature_dict: feature_dict[i]=max_features feature_list.append(i) max_features += 1 vector_x.append(feature_dict[i]) return vector_x defadd_to_data(input_s,output_s): iflen(input_s) < MAX_LENGTH_WORD andlen(output_s) < MAX_LENGTH_WORD: vector_x = get_vector_from_string(input_s) vector_y = get_vector_from_string(output_s) Xdata.append(vector_x) Ydata.append(vector_y)
defprint_vector(vector,end_token='\n'): print(''.join([feature_list[i] for i in vector]),end=end_token) withopen("dictionary_old_new_dutch.csv") as in_file: for line in in_file: in_s,out_s = line.strip().split(",") add_to_data(in_s,out_s) for i inrange(10): print_vector(Xdata[i],end_token='') print(' -> ', end='') print_vector(Ydata[i])
As mentioned above I would like to use a sequence to sequence approach. Important for this approach is having a certain length of words. Words that are longer than that length have been discarded in de data-reading step above. Now we will add paddings to the words that are not long enough. — 对于不够的词增加相应的padding
Another important step is creating a train and a test set. We only show the network examples from the train set. At the end I will manually evaluate some of the examples in the testset and discuss what the network learned. During training we train in batches with a small amount of data. With a random data splitter we get a different trainset every run. — 挑选合适的训练集和测试集
enc_input = [tf.placeholder(tf.int32, shape=(None,)) for i inrange(MAX_LENGTH_WORD)] dec_output = [tf.placeholder(tf.int32, shape=(None,)) for t inrange(MAX_LENGTH_WORD)]
weights = [tf.ones_like(labels_t, dtype=tf.float32) for labels_t in enc_input]
dec_inp = ([tf.zeros_like(enc_input[0], dtype=np.int32)]+[dec_output[t] for t inrange(MAX_LENGTH_WORD-1)]) empty_dec_inp = ([tf.zeros_like(enc_input[0], dtype=np.int32,name="empty_dec_input") for t inrange(MAX_LENGTH_WORD)])
cell = tf.nn.rnn_cell.GRUCell(memory_dim)
# Create a train version of encoder-decoder, and a test version which does not feed the previous input with tf.variable_scope("decoder1") as scope: outputs, _ = tf.nn.seq2seq.embedding_attention_seq2seq(enc_input,dec_inp, cell,max_features,max_features, embedding_dim, feed_previous=False) with tf.variable_scope("decoder1",reuse=True) as scope: runtime_outputs, _ = tf.nn.seq2seq.embedding_attention_seq2seq(enc_input,empty_dec_inp, cell,max_features,max_features, embedding_dim,feed_previous=True)
loss = tf.nn.seq2seq.sequence_loss(outputs, dec_output, weights, max_features)
for index_now inrange(1002): Xin,Yin = get_random_reversed_dataset(Xdata,Ydata,batch_size) Xin = np.array(Xin).T Yin = np.array(Yin).T feed_dict = {enc_input[t]: Xin[t] for t inrange(MAX_LENGTH_WORD)} feed_dict.update({dec_output[t]: Yin[t] for t inrange(MAX_LENGTH_WORD)}) _, l = sess.run([train_op,loss], feed_dict) if index_now%100==1: print(l)
defget_reversed_max_string_logits(logits): string_logits = logits[::-1] concatenated_string = "" for logit in string_logits: val_here = np.argmax(logit) concatenated_string += feature_list[val_here] return concatenated_string defprint_out(out): out = list(zip(*out)) out = out[:10] # only show the first 10 samples for index,string_logits inenumerate(out): print("input: ",end='') print_vector(Xin[index]) print("expected: ",end='') expected= Yin[index][::-1] print_vector(expected) output = get_reversed_max_string_logits(string_logits) print("output: " + output) print("==============")
# Now run a small test to see what our network does with words RANDOM_TESTSIZE = 5 Xin,Yin = get_random_reversed_dataset(Xtest,Ytest,RANDOM_TESTSIZE) Xin_transposed = np.array(Xin).T Yin_transposed = np.array(Yin).T feed_dict = {enc_input[t]: Xin_transposed[t] for t inrange(MAX_LENGTH_WORD)} out = sess.run(runtime_outputs, feed_dict) print_out(out)
deftranslate_single_word(word): Xin = [get_vector_from_string(word)] Xin = sequence.pad_sequences(Xin, maxlen=MAX_LENGTH_WORD) Xin_transposed = np.array(Xin).T feed_dict = {enc_input[t]: Xin_transposed[t] for t inrange(MAX_LENGTH_WORD)} out = sess.run(runtime_outputs, feed_dict) return get_reversed_max_string_logits(out)
interesting_words = ["aerde","duyster", "salfde", "ontstondt", "tusschen","wacker","voorraet","gevreeset","cleopatra"] for word in interesting_words: print(word + " becomes: " + translate_single_word(word).replace("~",""))
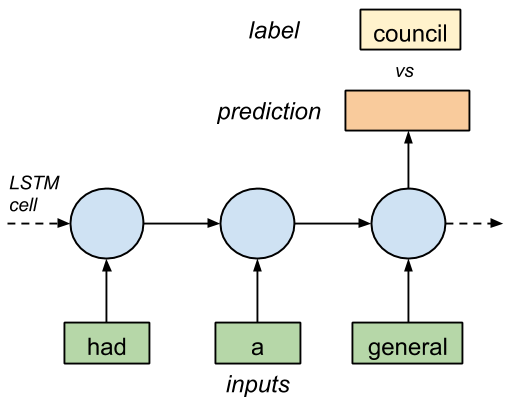
Figure 1. LSTM cell with three inputs and 1 output.
A way to convert symbol to number is to assign a unique integer to each symbol based on frequency of occurrence
1 2 3 4 5 6 7
defbuild_dataset(words): count = collections.Counter(words).most_common() dictionary = dict() for word, _ in count: dictionary[word] = len(dictionary) reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys())) return dictionary, reverse_dictionary
上面就是采用通过词频的方式,来进行转化编码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
defRNN(x, weights, biases):
# reshape to [1, n_input] x = tf.reshape(x, [-1, n_input])
# Generate a n_input-element sequence of inputs # (eg. [had] [a] [general] -> [20] [6] [33]) x = tf.split(x,n_input,1)
# 1-layer LSTM with n_hidden units. rnn_cell = rnn.BasicLSTMCell(n_hidden)
# generate prediction outputs, states = rnn.static_rnn(rnn_cell, x, dtype=tf.float32)
# there are n_input outputs but # we only want the last output return tf.matmul(outputs[-1], weights['out']) + biases['out']
Final notes:
Using int to encode symbols is easy but the “meaning” of the word is lost. Symbol to int is used to simplify the discussion on building a LSTM application using Tensorflow. Word2Vec is a more optimal way of encoding symbols to vector.
One-hot vector representation of output is inefficient especially if we have a realistic vocabulary size. Oxford dictionary has over 170,000 words. The example above has 112. Again, this is only for simplifying the discussion.
The number of inputs in this example is 3, see what happens when you use other numbers (eg 4, 5 or more).
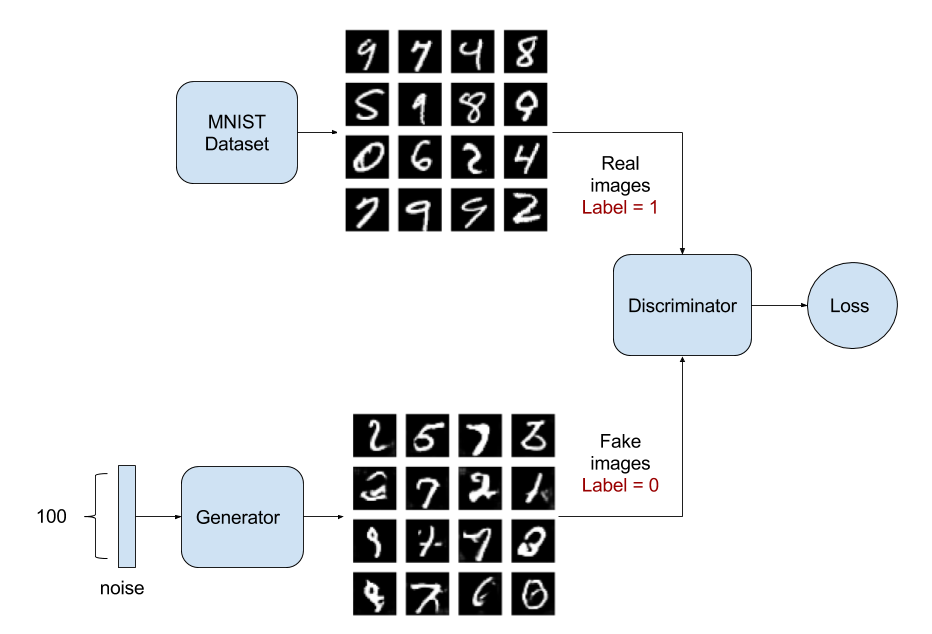
GAN is almost always explained like the case of a counterfeiter (Generative) and the police (Discriminator). Initially, the counterfeiter will show the police a fake money. The police says it is fake. The police gives feedback to the counterfeiter why the money is fake. The counterfeiter attempts to make a new fake money based on the feedback it received. The police says the money is still fake and offers a new set of feedback. The counterfeiter attempts to make a new fake money based on the latest feedback. The cycle continues indefinitely until the police is fooled by the fake money because it looks real
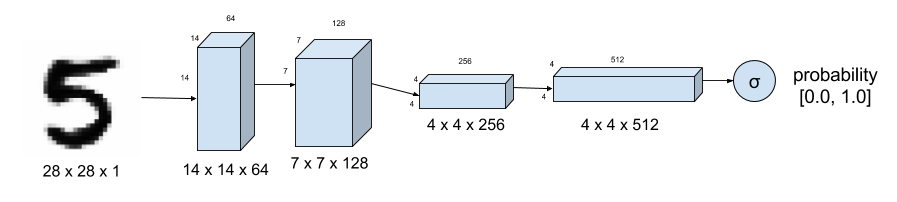
Figure 1. Discriminator of DCGAN tells how real an input image of a digit is. MNIST Dataset is used as ground truth for real images. Strided convolution instead of max-pooling down samples the image.
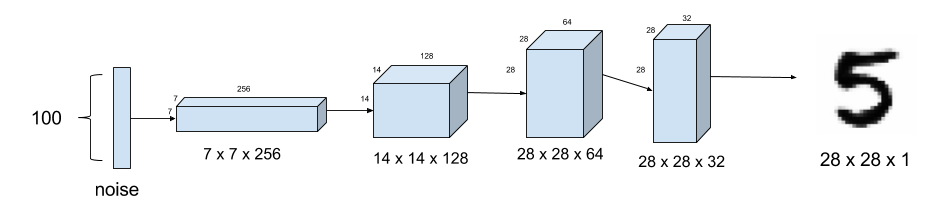
self.G = Sequential() dropout = 0.4 depth = 64+64+64+64 dim = 7 # In: 100 # Out: dim x dim x depth self.G.add(Dense(dim*dim*depth, input_dim=100)) self.G.add(BatchNormalization(momentum=0.9)) self.G.add(Activation('relu')) self.G.add(Reshape((dim, dim, depth))) self.G.add(Dropout(dropout))
# In: dim x dim x depth # Out: 2*dim x 2*dim x depth/2 self.G.add(UpSampling2D()) self.G.add(Conv2DTranspose(int(depth/2), 5, padding='same')) self.G.add(BatchNormalization(momentum=0.9)) self.G.add(Activation('relu'))
Training GAN models requires a lot of patience due to its depth. Here are some pointers:
Problem: generated images look like noise. Solution: use dropout on both Discriminator and Generator. Low dropout values (0.3 to 0.6) generate more realistic images.
Problem: Discriminator loss converges rapidly to zero thus preventing the Generator from learning. Solution: Do not pre-train the Discriminator. Instead make its learning rate bigger than the Adversarial model learning rate. Use a different training noise sample for the Generator.
Problem: generator images still look like noise. Solution: check if the activation, batch normalization and dropout are applied in the correct sequence.
Problem: figuring out the correct training/model parameters. Solution: start with some known working values from published papers and codes and adjust one parameter at a time. Before training for 2000 or more steps, observe the effect of parameter value adjustment at about 500 or 1000 steps.
The main characteristic of C types is the memory layouts of their values are transparent
Go can also be viewed as C language framework. This is mainly reflected in the fact that Go supports several kinds of types whose value memory layouts are not totally transparent. Each values of the these kinds of types is often composed of one direct part and one or several underlying indirect parts, and the underlying value part is referenced by the direct value part
Two kinds points
If a struct value a has a pointer field b which references a value c, then we can say the struct value a also (indirectly) references value c.
If a value x references (either directly or indirectly) a value y, and the value y references (either directly or indirectly) a value z, then we can also say the value x (indirectly) references value z
// map types type _map *hashtableImpl // currently, for the standard Go compiler, // Go maps are hashtables actually.
// channel types type _channel *channelImpl
// function types type _function *functionImpl
// slice types type _slice struct { elements unsafe.Pointer // underlying elements lenint// number of elements capint// capacity }
// string types type _string struct { elements *byte// underlying bytes lenint// number of bytes }
// general interface types type _interface struct { dynamicTypeInfo *struct { dynamicType *_type // the dynamic type methods []*_function // implemented methods } dynamicValue unsafe.Pointer // the dynamic value }
underlying value parts are not copied in value assignments
In Go, each value assignment (including parameter passing, etc) is a shallow value copy if the involved destination and source values have the same type (if their types are different, we can think that the source value will be implicitly converted to the destination type before doing that assignment). In other words, only the direct part of the soruce value is copied to the destination value in an value assignment. If the source value has underlying value part(s), then the direct parts of the destination and source values will reference the same underlying value part(s), in other words, the destination and source values will share the same underlying value part(s).
Here I just list some absolutely misuses of reference
only slice, map, channel and function types are reference types in Go. (If we do need the reference type terminology in Go, then we shouldn’t exclude any custom pointer and pointer wrapper types from reference types).
references are opposites of values. (If we do need the reference value terminology in Go, then please view reference values as special values, instead of opposites of values.)
some parameters are passed by reference. (Sorry, all parameters are passed by copy in Go.)
line break rules in go
One rule we often obey in practice is, we should not put the a starting curly brace ({) of the explicit code block of a control flow block on a new line.
1 2
for i := 5; i > 0; i-- { }
However, there are some exceptions for the rule mentioned above. For example, the following bare for loop block compiles okay.
funcmain() { listener, err := net.Listen("tcp", ":12345") if err != nil { log.Fatalln(err) } for { conn, err := listener.Accept() if err != nil { log.Println(err) } // Handle each client connection in a new goroutine. go ClientHandler(conn) } }
funcClientHandler(c net.Conn) { deferfunc() { if v := recover(); v != nil { log.Println("client handler panic:", v) } c.Close() }() panic(errors.New("just a demo.")) // a demo-purpose panic }
funcshouldNotExit() { for { time.Sleep(time.Second) // simulate a workload // Simultate an unexpected panic. if time.Now().UnixNano() & 0x3 == 0 { panic("unexpected situation") } } }
funcNeverExit(name string, f func()) { deferfunc() { if v := recover(); v != nil { // a panic is detected. log.Println(name, "is crashed. Restart it now.") go NeverExit(name, f) // restart } }() f() }
funcmain() { log.SetFlags(0) go NeverExit("job#A", shouldNotExit) go NeverExit("job#B", shouldNotExit) select{} // blocks here for ever }
funcdoTask(n int) { if n%2 != 0 { // Create a demo-purpose panic. panic(fmt.Errorf("bad number: %v", n)) } return }
funcdoSomething() (err error) { deferfunc() { // The ok return must be present here, otherwise, // a panic will be created if no errors occur. err, _ = recover().(error) }()
funcmain() { fmt.Println(doSomething()) // bad number: 53 }
close channel
One general principle of using Go channels is don’t close a channel from the receiver side and don’t close a channel if the channel has multiple concurrent senders. In other words, you should only close a channel in a sender goroutine if the sender is the only sender of the channel.
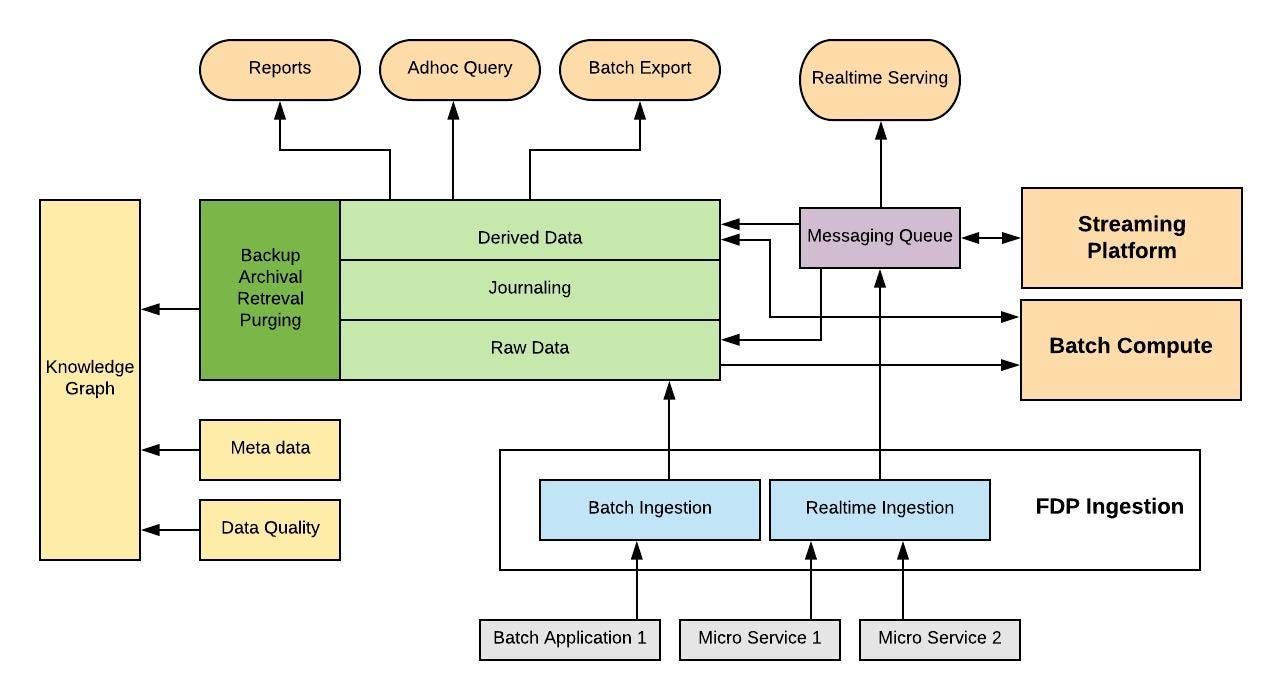
To give some perspective on the data scale at Flipkart, FDP currently manages a 800+ nodes Hadoop cluster to store more than 35 PB of data. We also run close to 25,000 compute pipelines on our Yarn cluster. Daily TBs of data is ingested into FDP and it also handles data spikes because of sale events. The tech stack majorly comprises of HDFS, Hive, Yarn, MR, Spark, Storm & other API services supporting the meta layer of the data
Overall FDP can be broken down into following high level components.
Ingestion System
Batch Data Processing System
Real time Processing System
Report Visualization
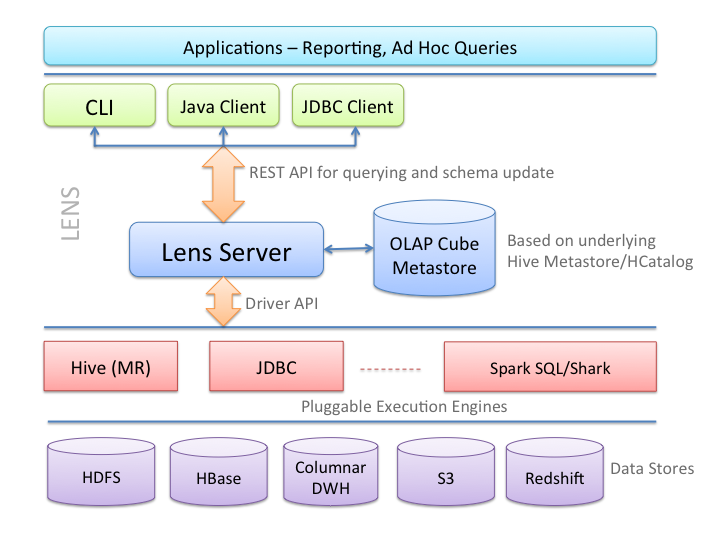
Query Platform
The streaming platform allows near real time aggregations to be built on all the ingested data. We also have the ability of generating rolling window aggregations i.e. 5 mins, 1 hour, 1 day, 1 month or Historic for each of the metrics.
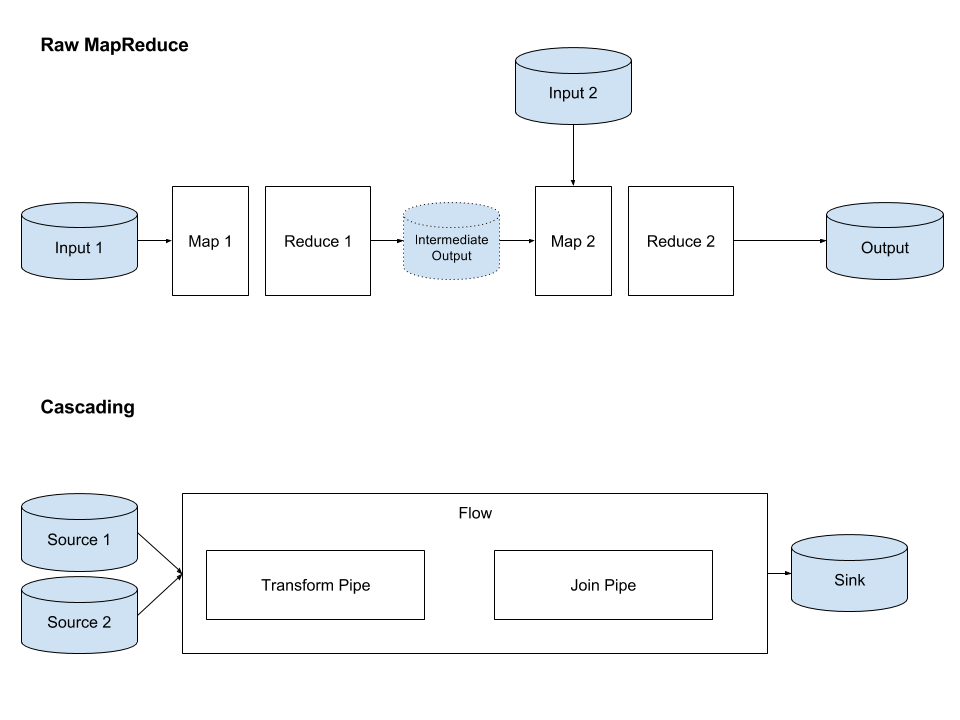
At the onset of Recommendation platform, we started with raw MapReduce(MR) which gave us granular control over our pipeline but required a lot of boilerplate code for performing joins and aggregations that constituted the building blocks of our ETL flow
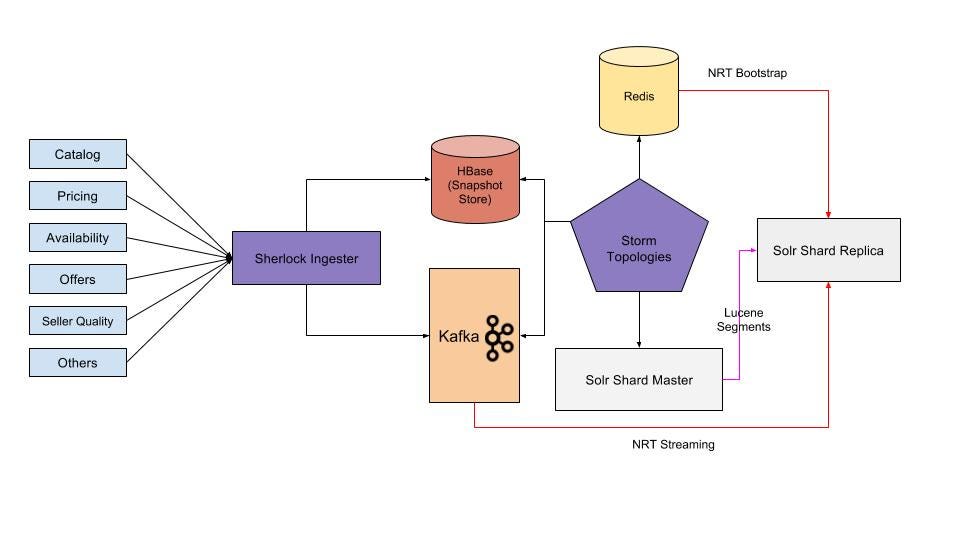
The Sherlock team developed an innovative solution (NRT data store) to deliver near real-time search results and presented it at Lucene Revolution video