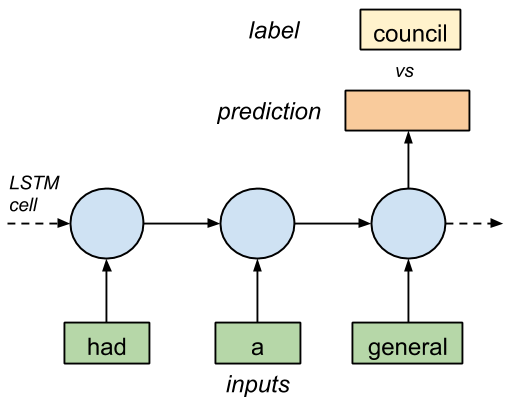
Figure 1. LSTM cell with three inputs and 1 output.
A way to convert symbol to number is to assign a unique integer to each symbol based on frequency of occurrence
def build_dataset(words):
count = collections.Counter(words).most_common()
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return dictionary, reverse_dictionary上面就是采用通过词频的方式,来进行转化编码
def RNN(x, weights, biases):
# reshape to [1, n_input]
x = tf.reshape(x, [-1, n_input])
# Generate a n_input-element sequence of inputs
# (eg. [had] [a] [general] -> [20] [6] [33])
x = tf.split(x,n_input,1)
# 1-layer LSTM with n_hidden units.
rnn_cell = rnn.BasicLSTMCell(n_hidden)
# generate prediction
outputs, states = rnn.static_rnn(rnn_cell, x, dtype=tf.float32)
# there are n_input outputs but
# we only want the last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']Final notes:
- Using int to encode symbols is easy but the “meaning” of the word is lost. Symbol to int is used to simplify the discussion on building a LSTM application using Tensorflow. Word2Vec is a more optimal way of encoding symbols to vector.
- One-hot vector representation of output is inefficient especially if we have a realistic vocabulary size. Oxford dictionary has over 170,000 words. The example above has 112. Again, this is only for simplifying the discussion.
- The number of inputs in this example is 3, see what happens when you use other numbers (eg 4, 5 or more).
想法:
- one hot的进化?词语太多的话,数组170000?左右
- 关于word的meaning部分,采用word2vec的方式,
- 关于input的参数的使用?如何使用?