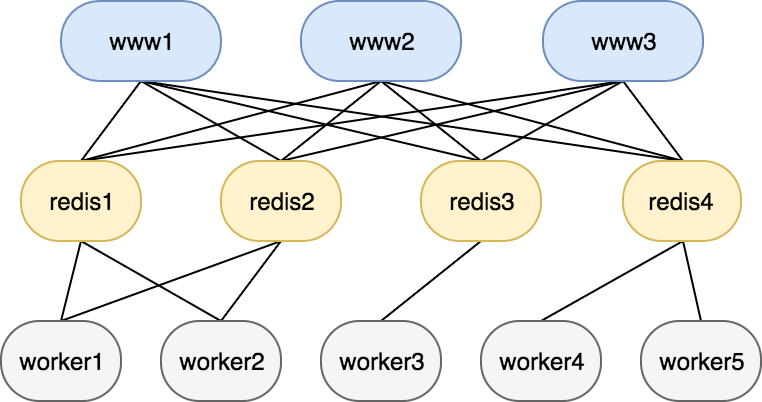
initial job queue system architecture
job with an identical ID
Pools of worker machines poll the Redis clusters, looking for new work. When a worker finds a job in one of the queues it monitors, it moves the job from the pending queue to a list of in-flight jobs, and spawns an asynchronous task to handle it.
Architectural Problems
- Redis had little operational headroom, particularly with respect to memory. If we enqueued faster than we dequeued for a sustained period, we would run out of memory and be unable to dequeue jobs (because dequeuing also requires having enough memory to move the job into a processing list).
- Redis connections formed a complete bipartite graph — every job queue client must connect to (and therefore have correct and current information on) every Redis instance.
- Job workers couldn’t scale independently of Redis — adding a worker resulted in extra polling and load on Redis. This property caused a complex feedback situation where attempting to increase our execution capacity could overwhelm an already overloaded Redis instance, slowing or halting progress.
- Previous decisions on which Redis data structures to use meant that dequeuing a job requires work proportional to the length of the queue. As queues become longer, they became more difficult to empty — another unfortunate feedback loop.
- The semantics and quality-of-service guarantees provided to application and platform engineers were unclear and hard to define; asynchronous processing on the job queue is fundamental to our system architecture, but in practice engineers were reluctant to use it. Changes to existing features such as our limited deduplication were also extremely high-risk, as many jobs rely on them to function correctly.
We thought about replacing Redis with Kafka altogether, but quickly realized that this route would require significant changes to the application logic around scheduling, executing, and de-duping jobs. In the spirit of pursuing a minimum viable change, we decided to add Kafka in front of Redis rather than replacing Redis with Kafka outright. This would alleviate a critical bottleneck in our system, while leaving the existing application enqueue and dequeue interfaces in place.
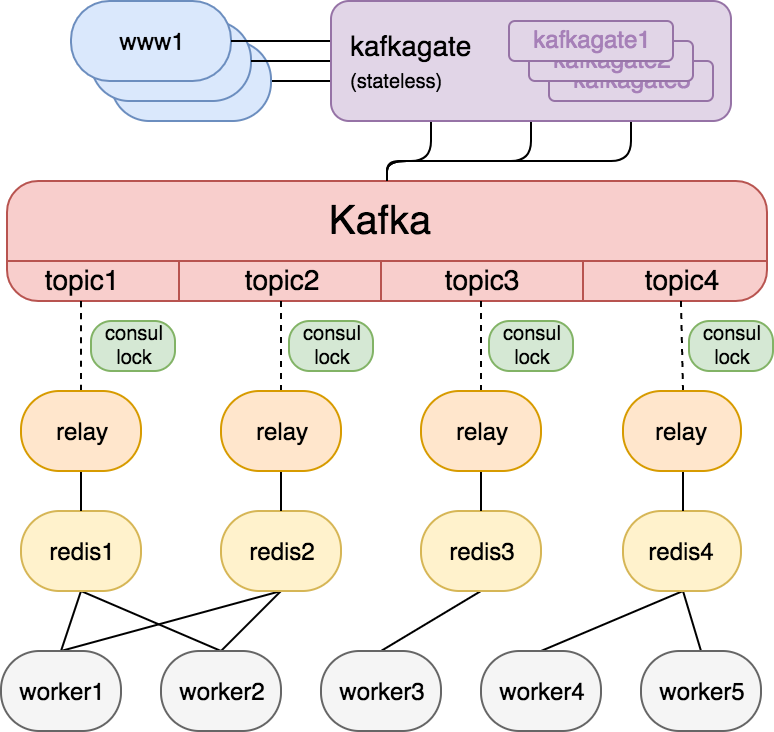
Kafka gate:
- A bias towards availability over consitency
- Simple client semantics
- Minimum latency
replay jobs from kafka to redis
use JQRelay to decode the JSON encoded job
Self-configuration: When a JQRelay instance starts up, it attempts to acquire a Consul lock on an key/value entry corresponding to the Kafka topic. If it gets the lock, it starts relaying jobs from all partitions of this topic. If it loses its lock, it releases all resources and restarts so that a different instance can pick up this topic.
load test
Failure testing: It was important to understand how different Kafka cluster failure scenarios would manifest in the application, e.g. connect failures, job enqueue failures, missing jobs, and duplicate jobs. For this, we tested our cluster against following failure scenarios:
- Hard kill and gracefully kill a broker
- Hard kill and gracefully kill two brokers in a single AZ
- Hard kill all three brokers to force Kafka to pick an unclean leader
- Restart the cluster
Production Rollout
Rolling out the new system included the following steps:
- Double writes: We started by double writing jobs to both the current and new system (each job was enqueued to both Redis and Kakfa). JQRelay, however, operated in a “shadow” mode where it dropped all jobs after reading it from Kafka. This setup let us safely test the new enqueue path from web app to JQRelay with real production traffic.
- Guaranteeing system correctness: To ensure the correctness of the new system, we tracked and compared the number of jobs passing through each part of the system: from the web app to Kafkagate, Kafkagate to Kafka, and finally Kafka to Redis.
- Heartbeat canaries: To ensure that the new system worked end-to-end for 50 Redis clusters and 1600 Kafka partitions (50 topics × 32 partitions), we enqueued heartbeat canaries for every Kafka partition every minute. We then monitored and alerted on the end-to-end flow and timing for these heartbeat canaries.
- Final roll-out: Once we were sure of our system correctness, we enabled it internally for Slack for a few weeks. After that showed no problems, we rolled it out one by one for various job types for our customers.