mysql的索引部分:关于最左匹配部分
在使用查询的时候遵循mysql组合索引的”最左前缀”,下面我们来分析一下 什么是最左前缀:及索引where时的条件要按照建立索引的时候字段的排序方式
1、不按索引最左列开始查询(多列索引) 例如index(‘c1’, ‘c2’, ‘c3’) where ‘c2’ = ‘aaa’ 不使用索引,where
c2=aaaandc3=sss不能使用索引
2、查询中某个列有范围查询,则其右边的所有列都无法使用查询(多列查询)
Where c1= ‘xxx’ and c2 like = ‘aa%’ and c3=’sss’ 改查询只会使用索引中的前两列,因为like是范围查询
3、不能跳过某个字段来进行查询,这样利用不到索引,比如我的sql 是
explain select * from
awardwhere nickname > ‘rSUQFzpkDz3R’ and account = ‘DYxJoqZq2rd7’ and created_time = 1449567822; 那么这时候他使用不到其组合索引.
因为我的索引是 (nickname, account, created_time),如果第一个字段出现 范围符号的查找,那么将不会用到索引,如果我是第二个或者第三个字段使用范围符号的查找,那么他会利用索引,利用的索引是(nickname),
mysql在使用like查询的时候只有不以%开头的时候,才会使用到索引。
给一个随时会断掉的输入流,取100个输入,保证尽可能的公平
先取100个,再按照一定的比率,取后面的数据,同时按照一定的概率对之前选取的数据进行替换,采用类似ping-pong的机制,通过一定概率进行替换
关于twitter的Finagle框架 rpc框架 同gRPC的区别?
都是rpc部分的框架,
关于goroutine的使用方面,关于使用了多少个goroutine,内存占用的情况
可能来说,监测内存占用情况,比较合适,runtime上去计算多少个goroutine上,有点不是很实用
go与java的区别
关于多线程的实现方式,一个是1:1对应到操作系统的线程,一个是n:m:p的方式,
finally以及defer之间
function部分多个返回值部分
部署的方便性部分,二进制文件以及jar包
在起多线程方式上,java还有哪些方式?thread/runnable/callable、future部分
nodejs的一些优缺点
事件驱动,非阻塞IO,单进程,单线程,callback机制,
emet的方式?
遇到I/O操作,会再起一个线程,不跟主线程冲突,适合I/O密集型应用
tcp的三次握手以及四次挥手
tcp为全双工的,
简单说来是 “先关读,后关写”,一共需要四个阶段。以客户机发起关闭连接为例:
1.服务器读通道关闭
2.客户机写通道关闭
3.客户机读通道关闭
4.服务器写通道关闭

IO模型
阻塞、非阻塞,针对应用来说,非阻塞也是轮询的那种
IO多路复用,主要是内核给出相关的信息,如select、poll、epoll
异步通讯,就是服务端来控制传输,无需客户端询问的那种
同步过程中进程触发IO操作并等待或者轮询的去查看IO操作是否完成。异步过程中进程触发IO操作以后,直接返回,做自己的事情,IO交给内核来处理,完成后内核通知进程IO完成
需要做一件事能不能立即得到返回应答,如果不能立即获得返回,需要等待,那就阻塞了,否则就可以理解为非阻塞
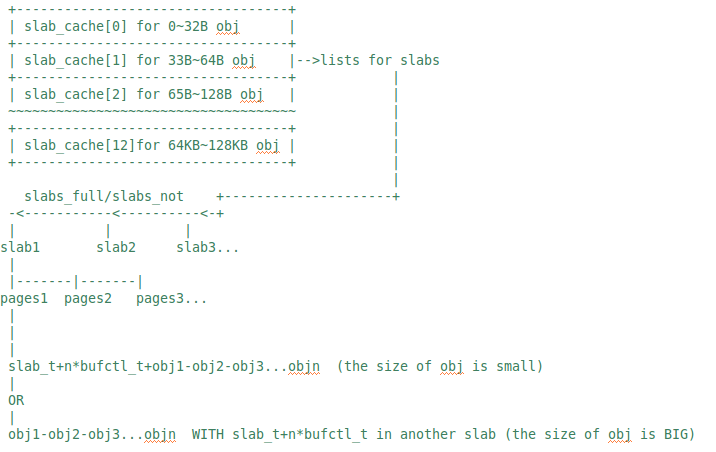
设计一个内存分配算法
slab算法
分布式系统的设计几个点
稳定性,不允许单点失效
尽可能减少节点间通讯开销
应用服务最好做成无状态的
CAP理论:一致性,可用性,分区容忍性(可靠性), 带来的一个问题,是ACID理论,(原子性,一致性,隔离性,持久性)
选主算法方面的问题,关于paxos算法的解释,以及raft协议的阐述
docker
适用于弹性部署的场景,例如抢购,秒杀,服务压力骤增,需要短时间增加容器。 同时适用于分布式情况,毕竟分布式部署应用还需要考虑,单点故障的情况。 还有就是异步处理任务,配合动态增减服务器,就可以节省资源,降低成本编排的目的:服务发现,高可用,资源管理,端口管理
各种编排的策略:swarm, k8s,双方提供的功能不同,
linux中buffers和cached
used:表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。
free:未被分配的内存。
shared:共享内存,一般系统不会用到,这里也不讨论。
buffers:系统分配但未被使用的buffers 数量。
cached:系统分配但未被使用的cache 数量
buffers是指用来给块设备做的缓冲大小,他只记录文件系统的metadata以及 tracking in-flight pages.
cached是用来给文件做缓冲。
那就是说:buffers是用来存储,目录里面有什么内容,权限等等。
而cached直接用来记忆我们打开的文件